 Espace client
Espace client
Détails :
Durée :
3 Jours
Prérequis :
Public :
Objectifs :
Le fine tuning, quant à lui, consiste à adapter un modèle pré-entraîné à des contextes spécifiques en affinant ses paramètres sur des données ciblées, améliorant ainsi sa performance pour des tâches précises.
Au terme de cette formation, vous saurez :
- Savoir décrire le fonctionnement et les limites d'un LLM.
- Comprendre les concepts clés du RAG.
- Savoir créer un Pipeline RAG avec LangChain.
- Comprendre les techniques de fine tuning sur un LLM.
- Evaluer et optimiser les performances de votre modèle.
- Savoir déployer votre modèle en production.
Demande de devis :
Devis :
Si vous souhaitez être contacté et obtenir plus d'informations sur cette formation
veuillez remplir notre formulaire de mise en relation.
Cursus de formation :
Cursus :
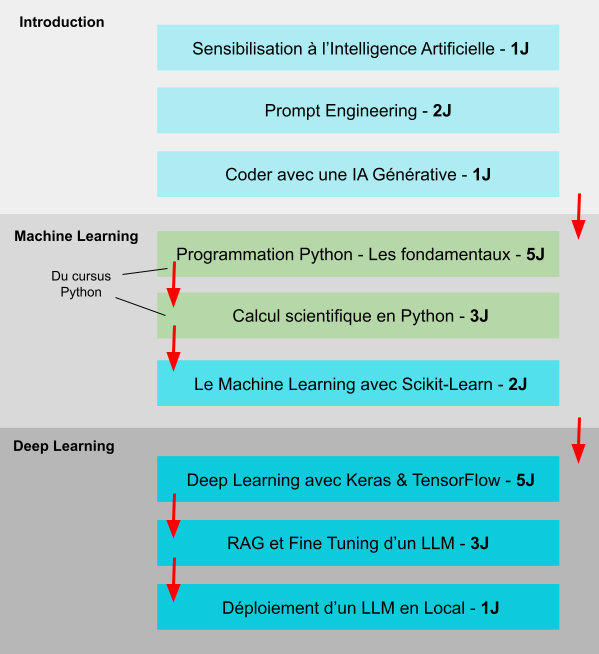
Programme détaillé de la formation :
- Rappels sur le Deep Learning
- Rappels sur l'architecture Transformer
- Forces et faiblesses d'un LLM
- Les principaux LLM à notre disposition
- Première utilisation de ces modèles
- Que sont le RAG et le Fine Tuning ?
- Les concepts clés du RAG
- Qu'est-ce qu'un embedding (un plongement) ?
- Word embedding VS Sentence embedding
- Bases de données vectorielle
- Indexation des données
- Chargement des données (PDF, Docx, Json, Web scraping, ...)
- La vectorisation des données (FAISS, ChromaDB, Weaviate)
- Les modèles d'embedding (Mistral-Embed, OpenAI, SentenceTransformers)
- Mécanisme de récupération des données
- Recherche sémantique
- Similarité cosinus, re-ranking
- Génération augmentée
- Techniques de prompt engineering
- Fusion des données récupérées avec un LLM
- Mise en oeuvre d'une interface graphiques avec Gradio
- Cas d'usage et enjeux stratégiques
- Applications du RAG dans l'industrie
- Mise en oeuvre agents conversationnels avec une base de connaissances personnalisée
- Pourquoi utiliser des Tool Chains ?
- Les principaux outils de Pipeline
- LangChain
- LlamaIndex
- Haystack
- Création d'un Pipeline RAG avec LangChain
- Configuration des outils
- Intégration des modèles de langage
- Exécution et test du Pipeline
- Agents LLM et logique ReAct
- Qu'est-ce qu'un agent LLM ?
- Qu'est ce que la Logique ReAct (Reasoning and Acting) ?
- Exemples d'agents avec LangChain
- Fine Tuning Complet VS Fine Tuning léger (LoRA, QLoRA...)
- Préparation des données
- Nettoyage et structuration des données
- Formats de fichiers utilisables (JSONL, HF datasets...)
- Stratégies d'annotation et de génération des prompts
- Augmentation des données
- Mise en oeuvre du Fine Tuning
- Les API utilisable
- Gestion des ressources GPU
- Évaluation et métriques de performance
- Distillation de modèles
- Quantization et compression d'un modèle
- Déploiement d'un modèle fine tuned
- Le logiciel Gradio
- Le déploiement en API via FastAPI
- Les logiciels Jan.ai et Ollama
- Comparaison entre les deux techniques
- Combiner les approches pour améliorer les performances
Introduction à l'IA générative et aux LLM
Le RAG (Retrieval Augmented Generation)
Mise en oeuvre d'un Pipeline pour votre RAG
Réaliser un Fine Tuning
Optimisation et déploiement
Fine Tuning VS RAG